"アニオタ社会復帰への道" の http://d.hatena.ne.jp/MikuHatsune/20130905 をやってみました.
最終的にこんな感じのグラフが出来ました.
使うライブラリ
library(knitr)
library(data.table)
library(png)
library(dplyr)
library(igraph)
まずは, データの取得です. Pixivの小説についたタグから, アツいカップリングを調べます.
## Pixivの小説についたタグから百合ネットワークを可視化したい
## ラブライブで検索して,
tag = "ラブライブ"
## 1000ページ分のデータを取りたい
page = 1000
## URLを生成
urls = paste("http://spapi.pixiv.net/iphone/search_novel.php?s_mode=s_tag&p=", seq(page), "&word=", tag, sep="")
## URLリストを作って吐き出す. コマンドからwget -iとする
write.table(urls, "urls.txt", row.names=FALSE, col.names=FALSE, quote=FALSE)
## files以下に保存
system("mkdir files")
system("wget -i urls.txt -P files/")
## タグの頻度を計算します
## ファイルリスト
fs = list.files(path = "files/")
## 格納先データフレーム
data0 = NULL
for(i in seq(fs)){
pb = txtProgressBar(min=1, max=length(fs), style=3)
setTxtProgressBar(pb,i)
data0 = rbind(data0, read.csv(paste("files/", fs[i], sep=""), header=FALSE))
}
データフレームの14列目にタグ情報が入っているので, そこに注目します.
## 各データフレームからタグを抽出
## 14列目に全部入っているので, そこを分解すればタグが得られる
## ここでuniqueとするのがよくわかっていないです
## tags = data0$V14 %>% as.character %>% strsplit(" ") %>% unlist
## tags_unique = data0$V14 %>% unique %>% as.character %>% strsplit(" ") %>% unlist
## tags_unique %>% write.table("tags_unique.txt", quote=FALSE, row.names=FALSE, col.names=FALSE)
tags_unique = fread("tags_unique.txt", header=FALSE) %>% unlist
tags_unique %>% head
## V11 V12 V13 V14 V15
## "海未の日" "園田海未" "南ことり" "高坂穂乃果" "ラブライブ!"
## V16
## "百合"
集計します.
## ミューズのメンバー
member = c("こと", "うみ", "ほの", "りん", "ぱな", "まき", "のぞ", "えり", "にこ")
member_english = c("Koto", "Umi", "Hono", "Rin", "Pana", "Maki", "Nozo", "Eri", "Nico")
## カップルに対応する要素が入っている行列
couple = outer(member, member, FUN = paste, sep="")
## 各カップルに対応する数字が入る行列
couple_tag_num = diag(0, length(member))
dimnames(couple_tag_num) = list(member, member)
# ## タグとカップル名が一致していたら, そのカップル名のtag_numを+1する
# for( i in 1:length(tags)){
# pb = txtProgressBar(min=1, max=length(tags), style=3)
# setTxtProgressBar(pb,i)
# couple_tag_num[couple == tags[i]] = couple_tag_num[couple == tags[i]] + 1
# }
## uniqueバージョンで集計アンド計算
for( i in 1:length(tags_unique)){
# pb = txtProgressBar(min=1, max=length(tags_unique), style=3)
# setTxtProgressBar(pb,i)
couple_tag_num[couple == tags_unique[i]] = couple_tag_num[couple == tags_unique[i]] + 1
}
couple_tag_num
## こと うみ ほの りん ぱな まき のぞ えり にこ
## こと 0 18 2 0 0 0 0 5 0
## うみ 4 0 1 2 1 2 0 4 1
## ほの 0 5 0 0 0 3 3 5 2
## りん 0 0 0 0 4 3 0 0 0
## ぱな 0 0 0 1 0 1 0 0 0
## まき 1 3 0 1 2 0 1 2 1
## のぞ 0 0 0 0 0 1 0 23 8
## えり 0 11 0 0 0 6 6 0 1
## にこ 0 2 1 0 0 19 8 1 0
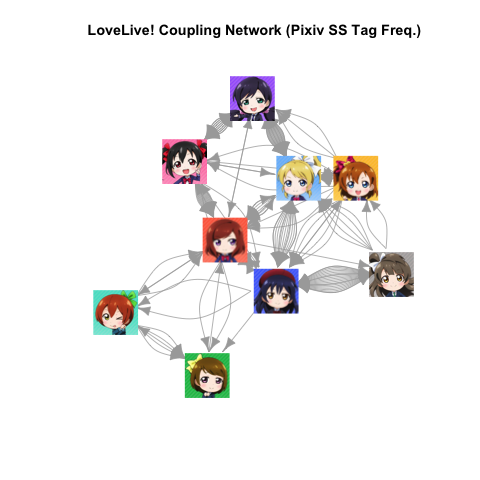
ネットワークグラフを作成.
## 日本語文字化けを直していないので, 英語に.
dimnames(couple_tag_num) = list(member_english, member_english)
## 接続行列を投げればいい
graph = graph.adjacency(couple_tag_num)
## グラフィカルパラメータの設定
set.seed(13)
V(graph)$size <- 30
V(graph)$color <- NA
V(graph)$frame.color <- NA
V(graph)$shape <- "square"
## plot. 配置は適当にやってもらう.
plot(graph, layout=layout.auto)
title("LoveLive! Coupling Network (Pixiv SS Tag Freq.)")

このままだと寂しいです. ノードに画像を載せます. 各メンバーのアイコンがあると, 心が安らぎます. まずは画像データの取得. images/に, 各メンバーに対応したアイコン画像.pngを用意しましたので, これらを読み込みます. 公式のツイッターアイコンとして配布されていましたので, 使用は自由...のはず.
pics = vector("list", 9)
for(i in 1:9){
pics[[i]] = readPNG(paste("images/", member_english[i], ".png", sep=""), native=TRUE)
}
次に, 読み込んだ画像データを, ネットワークグラフ上に載せます.
## なにこれ
ra = 1
## これもわからん ピクセルが入るらしい
xy0 = pics %>% sapply(dim)
rownames(xy0) = c("height", "width")
## 拡大縮小率
s0 = 0.0025
## 乱数の固定 グラフが固定されます.
set.seed(13)
## グラフィカルパラメータの設定
V(graph)$size <- 30
V(graph)$color <- NA
V(graph)$frame.color <- NA
V(graph)$shape <- "square"
## plot. 配置は適当にやってもらう.
plot(graph, layout=layout.auto)
title("LoveLive! Coupling Network (Pixiv SS Tag Freq.)")
## plotにのせていく
## 最初は, 座標を取得する
print(member_english)
## [1] "Koto" "Umi" "Hono" "Rin" "Pana" "Maki" "Nozo" "Eri" "Nico"
## この順番に位置をクリックして, ESCする
# lay0 = locator()
## lay0に座標が入る.
## 毎回やるのは面倒なので, 1回だけやって書き出しておく
#lay0 %>% write.table("layout.txt", row.names=FALSE, quote=FALSE)
## 前に取得しておいた座標を使う
lay0 = fread("layout.txt") %>% as.data.frame
for(i in 1:9){
## 位置を指定
## locatorで指定した位置が, 画像の中心座標となります.
## あとは, 4隅の座標を計算してあげます
xleft=lay0[i, 1]*ra - xy0[2, i]/2*s0
ybottom=lay0[i, 2]*ra - xy0[1, i]/2*s0
xright=lay0[i, 1]*ra + xy0[2, i]/2*s0
ytop=lay0[i, 2]*ra + xy0[1, i]/2*s0
## 指定した画像を載せます
rasterImage(image=pics[[i]], xleft=xleft, ybottom=ybottom, xright=xright, ytop=ytop, xpd=TRUE)
}

これでOK.
http://d.hatena.ne.jp/MikuHatsune/20130905 にこのぞが増えてますかね. 他は良くわかりません.